
Contact tracing works!

Welcome to Plugging the Gap (my email newsletter about Covid-19 and its economics). In case you don’t know me, I’m an economist and professor at the University of Toronto. I have written lots of books including, most recently, on Covid-19. You can follow me on Twitter (@joshgans) or subscribe to this email newsletter here.
The one thing social scientists know is that it is hard to establish whether an intervention works or not. Why? Because people are choosing whether to intervene or not. For instance, intuitively contract tracing helps reduce infections by proactively identifying and isolating those exposed to a virus. But if we observe one area that pursues contact tracing with fewer infections than another that doesn’t, does that mean contact tracing itself is reducing infections? That’s a possibility. But it could also be that contact tracing has been adopted precisely because there are fewer infections and so is more manageable. In other words, there is a theory that causation may go the other way.
The problem, of course, is that what you want to do in the interests of good ‘science’ is randomly assign some regions to contact trace and other regions to not contact trace and also, this is important, tell no one in those regions about the assignment. What gets in the way of this is ‘ethics’ because, frankly, if you think contact tracing is likely effective at reducing infections, it is surely bad to leave some region randomly out and, moreover, not tell people about it in case they want to take precautions.
To get over these quandaries, the way science progresses is if there is some cock-up that is plausibly random and unrelated to the scientific inquiry itself. Enter the UK and that Excel spreadsheet error that I wrote about last month. This was a cock-up where 15,000 people who were infected with Covid-19 were not properly recorded as being infected by public health authorities. What that meant was (a) they weren’t being contact traced and (b) no one knew about it until after the fact. This had all the ingredients of the experiment we would not ordinarily be ‘allowed’ to run. (I make light of this but as it will turn out doing so is admittedly highly inappropriate in the circumstances.)
Two economists, Thiemo Fetzer and Thomas Graeber saw the opportunity presented and began work. The first thing to determine was whether the impact of the error was distributed over enough regions with some hit harder than others to make all of this matter. In their paper, they found variation all over England.
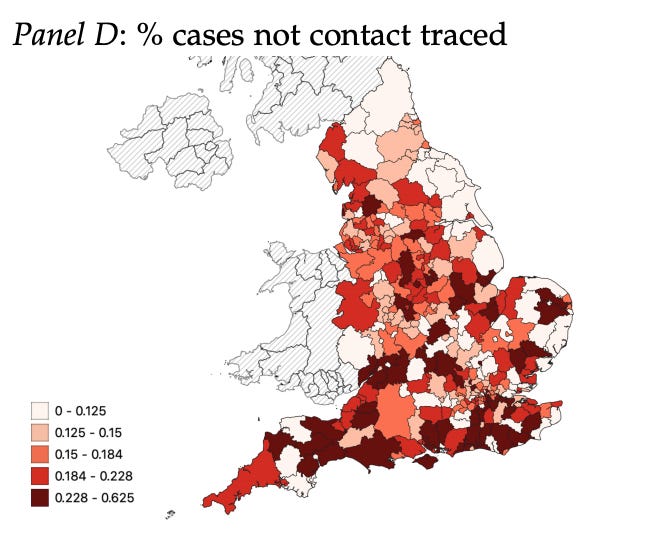
So far so good. Now the bad news. As it turns out, the areas where there was a bigger loss of contacts being traced, end up having worse outcomes subsequently.

Not only where there more cases per capita but more deaths too. The authors estimate 125,000 additional infections and 1,500 additional deaths from the Excel error. In all likelihood they are, if anything, understating the effects which could be twice as large. If that doesn’t underscore the point that we need better data management, I don’t know what does.
Nonetheless, this tells us something important. Contact tracing is valuable. It is hard, difficult to organise, expensive and if it is to be effective, needs to encroach on privacy rights. This error has produced the clearest evidence to date that this is valuable and even gives us a sense of how valuable.