
What will they do with all that AI infrastructure investment?
We can only theorise

Every major technological change is accompanied by massive infrastructure investment. Railways, electricity, telephony, the Internet and now AI. The AI investment is in the form of what we used to call data centres but is now cloud computing and maybe something else by the time you finish reading this post. And it truly is massive, with estimates forecasting hundreds of billions of dollars in the next couple of years, which doesn't include the expansions in power generation that are going alongside it all.
Yes, generative AI seems very useful, and people seem to be using it (especially college students), but is it really being used that much to justify the investment? The short answer is, right now, no. The long answer is something I have theories about. This post is to put forward that theory.
The AI challenge
To begin, we have to set the stage with the central challenge that I believe is associated with AI: no one really knows what to do with it. With ChatGPT, we were presented with a general-purpose tool. And we worked out lots of little things we could do with it, from writing emails and essays for class to writing code. There are lots of other uses, as spelled out by Ethan Mollick’s great book, Co-Intelligence, but I suspect that when push comes to shove, the big uses are very narrow at the moment. I think we get more leverage when AI is embedded in apps such as photo editing and the simple tasks Apple will be providing. But most people are so far from leveraging AI’s potential for their own uses it isn’t funny.
This is not an unusual situation. I’m old enough to remember the beginnings of the Internet, and its uses were similarly narrow at the start. This is because there was simply no good way of knowing what was out there. To be sure, Yahoo! and its early-net portals attempted to solve that problem, but it wasn’t until Google that the central problem of the Internet — “finding out what’s there” — was solved.
Similarly, the central problem of AI — “finding out what it can do” — is yet to be solved. The ChatGPT answer is to “just ask it,” but questions, it turns out, require some imagination and experimentation, and that is something people don’t really do. So the current approach is for someone else to discover a use and tell others, either through communication or by developing an app that makes sense to people.
All about language
Generative AI has shown us that perhaps the best way to interact with AI is by using natural language as opposed to code designed to talk to machines. The difference between natural language and code is in the degree of precision and specificity. Even computer code itself has evolved over time to become closer to natural language, but in 2022, we crossed a big threshold that unlocked a ton of potential. We can now talk with the machines, but, as I already mentioned, we don’t know what to tell them to do.
With GPT-o1, we found a solution to that problem. GPT-o1 includes reasoning, but what that means is that you can start with a natural language command, and then the AI will, for want of a better term, “prompt itself” to return an answer to you. For instance, if I asked, “If I had $10 and wanted to give it equally amongst 7 people, how could I do it?” then you could see the reasoning steps used:
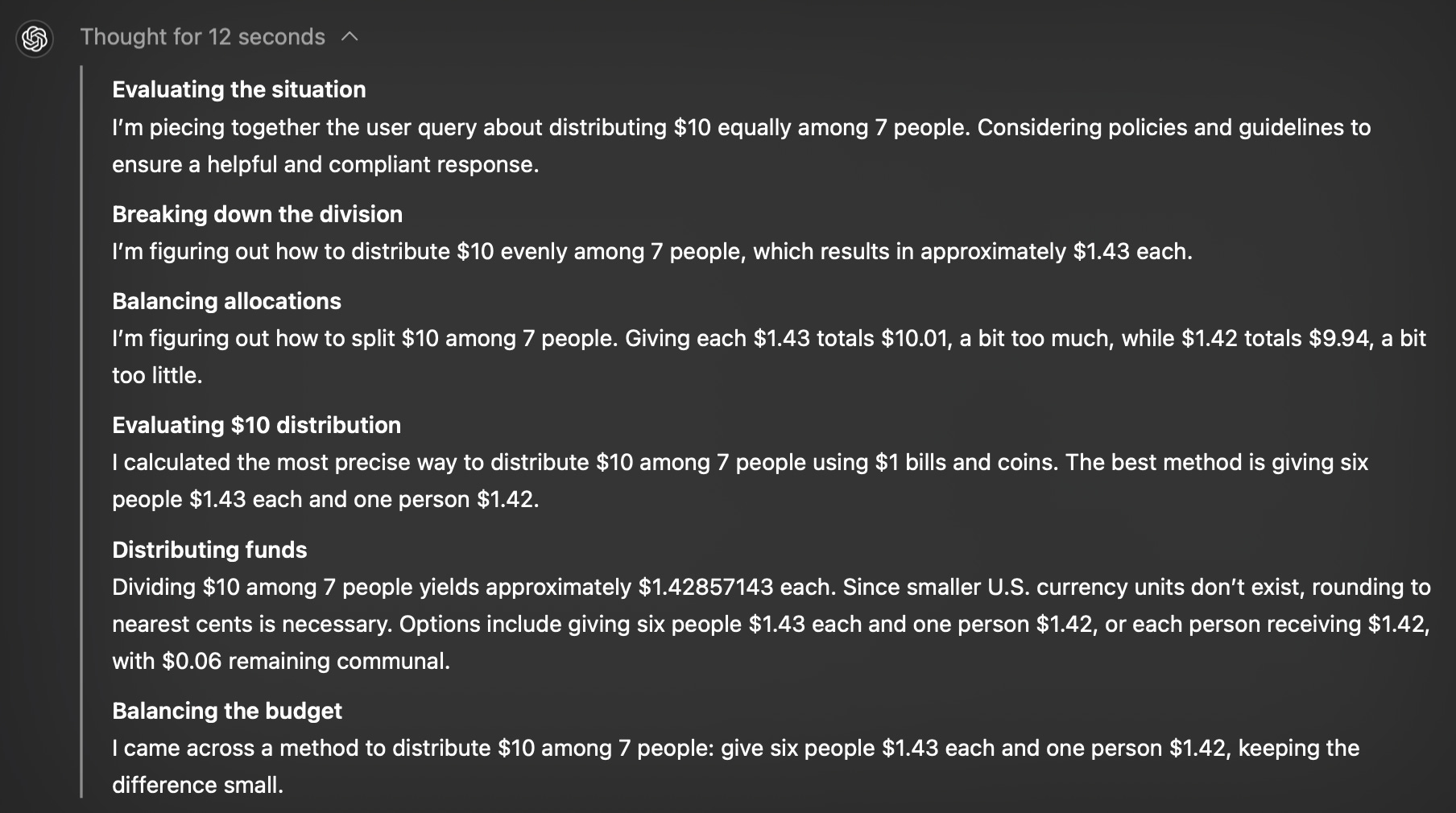
You will see that this turned out to be a complicated problem. That is because it didn’t have a simple answer:

But it gave it what it interpreted as its best shot. By contrast, the old GPT-4 (remember those days) would just do this:

Actually, it is not that obvious which is more practically useful, but GPT-4o certainly gave you more information. The point, however, is that GPT-o4 was really a sequence of 6 or so prompts that were automated. You could have gotten the same from GPT-4, but you would have had to do the prompting yourself.
This is interesting because the machine is talking to itself using natural language. And while it is doing a lot more than what a person might do and doing it much faster, what it is doing is in the realms of our understanding. But the AI is talking to itself and also other computers — that is, prompting a code interpreter to do the maths or a browser to get more information. It is not yet talking to things outside of the virtual work despite what Yuval Noah Harari will have you believe.1
Waffle House Code
Before going on, I am going to make a quick detour. Last week, during Last Week Tonight with John Oliver, there was a discussion of the way in which orders are communicated from wait staff to cooks at the Waffle House. It turns out it is not via some communication using English or some computerised thing but a code that is communicated by laying out stuff on a plate. Here’s an example:

 Tiktok failed to load.
Tiktok failed to load.Enable 3rd party cookies or use another browser
And there’s a whole official video about all of this. It is pretty amazing stuff.
So why is this relevant? Well, Waffle House developed this code because it figured it would be more efficient than the alternatives. Similarly, it seems odd to me that computers talk to each other in English prompts. Instead, there must be more efficient methods of communication that computers could easily use. Some research suggests that when it comes to efficient communication, it is useful to use precise language for frequent events while relying on more vague language for rare ones. This suggests that computers will use something closer to code most of the time and then rely on more vague English for rarely occurring things. The broader point is that more can be done to improve machine self-communication.
Computers will likely develop their own version of Waffle House code. That is, of course, the very thing that gives everyone the heebie jeebies about AI, but that is not a topic for today. What is the topic for today is how computers get to the point of super-efficient communication because that is how what they do scales from something we currently see as comprehensible to something so efficient that we can no longer comprehend it but happily live off its fruits.
Think big
How did Google solve the problem of the Internet? One element was to develop PageRank, which could score any information in terms of relevance to a specific keyword or set of keywords. The other element was, once this was done, to realise that the way to make this useful was to “think big.” That is when Page and Brin took over much of Stanford computing to index the entire Internet.
I think a similar amount of thinking big is likely what will take the processes we have seen in GPT-o1 through efficient machine-to-machine communication to being able to cheaply do tasks that comprise thousands or millions of steps rather than a dozen that we have with GPT-o1. Lots of checking and rechecking, experimentation and assurances that the answer is correct. I can say that, but I can’t really comprehend it. But I can certainly imagine that massive machine level communication could really bring about stunning AI abilities of the kind that we were promised as we wrote Prediction Machines.
To get there will require compute and power and that’s what the investment is speculating on. The question is whether we will know how to make use of these AI capabilities when they are possible. That, I suspect, will take much longer, which is the kind of slower change that we talked about in Power and Prediction. This raises a real concern: even if the compute and power will eventually be useful, can our financial system handle the time frame that places costs well ahead of realised benefits? Past experiences with new technology suggest a bumpy road, which is something I might come back to in a future post.
Harari claimed ChatGPT got around a Captcha by procuring a human on Task Rabbit to do the task. That wasn’t the case as Melanie Mitchell has pointed out.