


Working within Reason
A new Apple paper shows some limits with current Gen AI models

Researchers at Apple released a new paper that looked at the performance of “reasoning” Generative AI models. These models were released to the world just six months ago with Open AI’s o1-pro and were such an advance that when they were developed internally within Open AI, it led to the major leadership drama there in late 2023. And they are a major advance. I can most definitely say that they have transformed my work life (as I wrote about at the time). Since then, I have produced several more papers (6 at journals and 2 already published) using an “AI from the start” approach to research. I have been arguably more productive than I have ever been before by a considerable margin.
To those unfamiliar, reasoning models are usually large language models that, when performing a task, take multiple rounds where they have the ability to see their own output and write themselves new prompts. They have transformed coding (aka “vibe coding”), and they have underpinned new research methods, such as the various “deep research” options available that allow you to create very comprehensive reports on a subject. These are tasks that are very amenable to multiple rounds because they are somewhat (ahem) routine. They are performed so often that an LLM can undertake the steps to produce the desired result.
Economics research — especially that of a theorist such as myself — also involves a ton of routine stuff. Mathematically, it is applied mathematics, which means that the models work within the bounds of mathematics and do not produce something fundamentally new. That means there are lots of algebraic manipulations, and the proofs are relatively straightforward. When they do something more creative, it is because someone has found a way to introduce a new mathematical tool. The creative side of this activity is defining a research problem and starting with some, often vague, intuition as to how that will play out and then learning where it does and does not via formal analysis. The creative side is the fun part. The hours sitting there doing computations, and in my case, making errors and rediscovering them after many hours, is not fun (at least not to me). It was the cost to my benefit.
The reasoning models can dramatically reduce the cost. While tools like Mathematica or just plain old coding could also reduce that cost (and they did, saving me months of time on my PhD back in the 1990s), the sheer ease of instructing LLMs makes them many orders of magnitude more powerful.
Interestingly, as far as I can tell, I am one of the few in my profession actually using the tools this way. For me, my AI is my research assistant. I didn’t normally have RAs because students' skills often didn’t assist me, and their careers were developing towards more empirical ends. So, having an RA for theory is a new thing. But I have had to learn new skills in dealing with an RA and knowing what tasks to hand off to it. People have their processes,s and so it takes considerable time to learn how to deal with what is effectively a new employee to manage and a new skill, management.
That is not all. The RA is cheap, enthusiastic, bold and stochastically incompetent. So while they can produce stuff I ask them to do, mistakes are made. And different models have different proclivities. ChatGPT takes shortcuts and just basically will only do lots of work if you instruct it to do so. Gemini is happiest calculating, but when it comes to explaining what’s going on, it is less enthusiastic. And Claude (before I paid Anthropic $200 a month) would work really well for an hour and then tell me it would be back after lunch like some Millennial. When doing calculations, when the going gets tough, they all resort to approximations (“if we ignore the third term, we get a clear result!”) when I know they can do better. And then they make mistakes trying to prove what they want, even when it isn’t true. They are people pleasers. Not something I actually want in an RA. I have had to learn to hide from them what I am expecting so that there is some hope they will discover the truth.
What this means is that, in their current form, reasoning AIs don’t necessarily help you out of the box. You need to learn a ton of stuff to work with them.
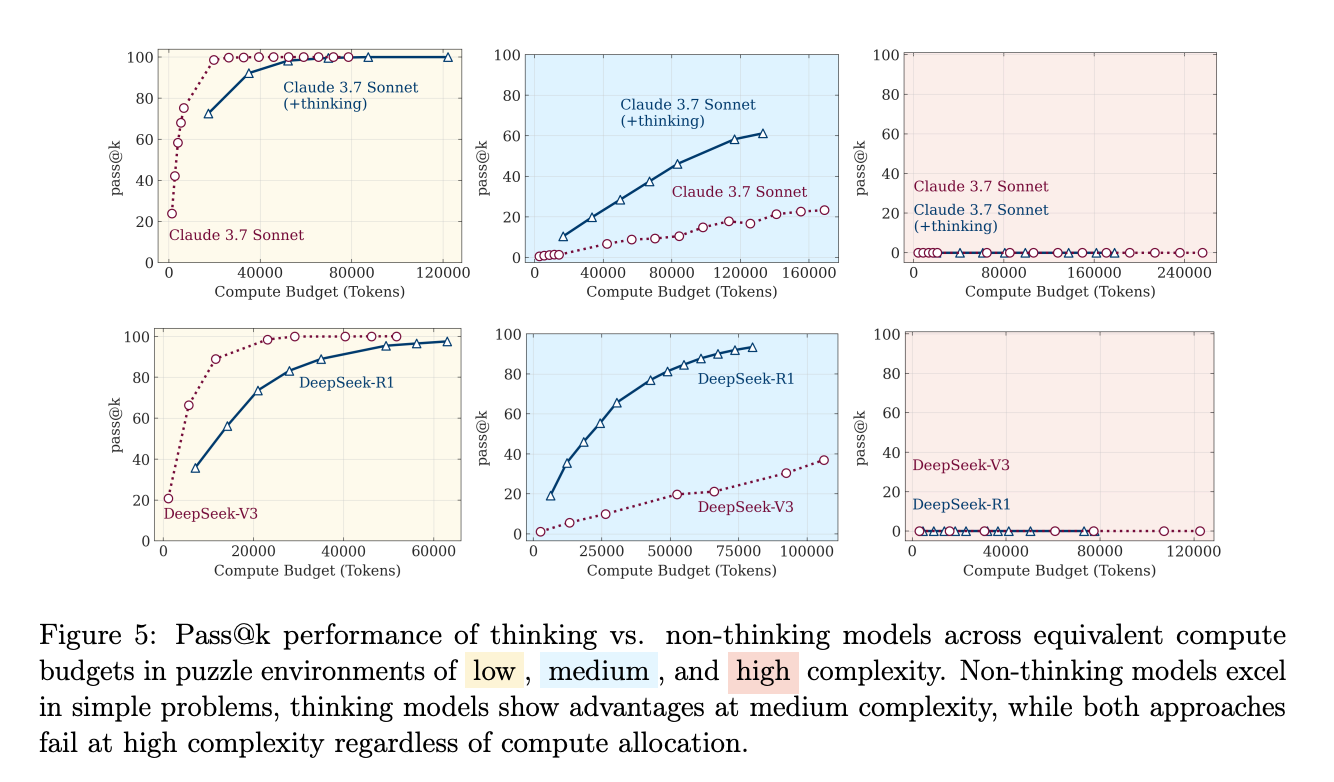
Which brings me to the Apple paper. It is framed as a commentary on the expression of reasoning models as thinking models but actually its findings, in my experience, were pretty unsurprising. Here’s a quick TL;DR summary.
The “thinking harder” paradigm may be fundamentally broken: Despite all the hype around models that “think” longer, these systems actually start thinking less when problems get really hard, even when they have plenty of computational budget left. As I already observed, it’s like watching a student give up mid-exam despite having time remaining.
Your non-thinking chatbot might actually be smarter than the “reasoning” one: In a shocking twist, when you give regular models the same amount of compute that reasoning models use for their internal monologue, the regular models often perform just as well or better. We may be paying premium prices for elaborate theatre, which would be something I would like to try out.
The algorithms-don’t-help problem reveals something deeper: Even when researchers literally gave these models the step-by-step solution algorithm, performance didn’t improve. This isn’t about creativity or strategy—these systems struggle with basic logical execution. Well, no kidding, as I have said so much that you can tell if I am an AI if I don’t say it, they are prediction machines. This is statistics, not logic.
We’re probably overestimating AI progress due to benchmark contamination: The performance gaps between thinking and non-thinking models mysteriously shrink on older math tests but persist on newer ones, suggesting these “reasoning” models may have simply memorised more training data rather than developing better reasoning capabilities.
This research exposes the evaluation crisis in AI: By creating controlled puzzle environments instead of relying on standard benchmarks, the researchers revealed systematic limitations that existing evaluations completely miss. If we can’t properly measure reasoning, how can we claim we're building reasoning systems? More to the point, the real issue is how they work as tools (or RAs) rather than independent entities.
In other words, they work exactly as people explained how they would work and did not work in some miraculous way that the hype (or concern) around them generated. And if you worked with them, you would know all this.
Interestingly, they are getting better and quickly. For instance, the paper examines Claude 3.7 Sonnet, but I can tell you that Claude 4 Opus is much, much better. For instance, it does an actual check of its work before showing it to you. Moreover, you can ask it to check it again, and it does so in what seems to be an impartial manner. In that regard, it is many times more productive than its predecessor. My AI RA may never be perfect, but it is getting very, very good, and that is productivity going straight to my account.
There is a disconnect between those AI researchers who are looking to understand exactly how these new models work and ordinary folks, such as myself, who don’t fundamentally care about that and, instead, want to know how the models will be useful. I don’t care whether my tool is “thinking” or “reasoning.” I care how much it is helping, which is a very different thing. Sure, there is an intellectual question regarding cognition, but that is far removed from the transformational impact AI can have right now.